Documentation Index
Fetch the complete documentation index at: https://mintlify.com/ByteByteGoHq/system-design-101/llms.txt
Use this file to discover all available pages before exploring further.
Overview
Cloud computing and distributed systems are the backbone of modern software architecture. They enable us to build scalable, reliable, and high-performance systems. This guide covers the fundamental concepts, best practices, and real-world examples of cloud computing and distributed systems.Cloud Computing Fundamentals
Cloud Service Models
Infrastructure as a Service (IaaS)- Virtual machines, storage, networks
- Examples: AWS EC2, Azure VMs, Google Compute Engine
- Use Case: Maximum control over infrastructure
- Managed runtime environments, databases
- Examples: AWS Elastic Beanstalk, Google App Engine, Heroku
- Use Case: Focus on application, not infrastructure
- Complete applications delivered over internet
- Examples: Gmail, Salesforce, Office 365
- Use Case: Ready-to-use applications
- Serverless compute, event-driven execution
- Examples: AWS Lambda, Azure Functions, Google Cloud Functions
- Use Case: Event-driven, short-lived computations
Major Cloud Providers
AWS
Market leader with broadest service portfolio. Strong in enterprise and startups.
Azure
Excellent Microsoft integration. Strong enterprise presence and hybrid cloud.
Google Cloud
Leader in AI/ML and data analytics. Strong Kubernetes and container support.
Distributed Systems Concepts
CAP Theorem
In a distributed system, you can only guarantee two of three properties:- Consistency: All nodes see the same data at the same time
- Availability: Every request receives a response
- Partition Tolerance: System continues operating despite network failures
Consistency Models
Strong Consistency- All reads return the most recent write
- Higher latency, lower availability
- Examples: Traditional RDBMS, ZooKeeper
- All replicas eventually converge to same state
- Higher availability, lower latency
- Examples: DynamoDB, Cassandra, DNS
- Maintains order of causally related operations
- Middle ground between strong and eventual
- Examples: Some distributed databases
Scalability Patterns
Horizontal vs Vertical Scaling
Vertical Scaling (Scale Up)- Add more resources to a single machine
- Simpler but limited by hardware
- Single point of failure
- Add more machines to distribute load
- More complex but unlimited potential
- Better fault tolerance
Load Balancing
Distribute traffic across multiple servers:- Round Robin: Rotate through servers sequentially
- Least Connections: Send to server with fewest active connections
- IP Hash: Route based on client IP address
- Weighted: Distribute based on server capacity
- Least Response Time: Route to fastest responding server
Auto-Scaling
Automatically adjust resources based on demand:- Reactive: Scale based on current metrics (CPU, memory)
- Predictive: Scale based on predicted future load
- Scheduled: Scale based on known patterns
High Availability Design
Key Principles
- Redundancy: Eliminate single points of failure
- Replication: Maintain multiple copies of data
- Failover: Automatic switching to standby system
- Health Checks: Continuously monitor system health
- Circuit Breakers: Prevent cascading failures
Availability Metrics
- 99.9% (Three Nines): 8.76 hours downtime/year
- 99.99% (Four Nines): 52.6 minutes downtime/year
- 99.999% (Five Nines): 5.26 minutes downtime/year
Each additional “nine” of availability typically costs 10x more to achieve.
Distributed System Patterns
Microservices Architecture
Benefits:- Independent deployment and scaling
- Technology diversity
- Fault isolation
- Team autonomy
- Distributed system complexity
- Network latency
- Data consistency
- Operational overhead
Event-Driven Architecture
- Services communicate through events
- Loose coupling between components
- Better scalability and resilience
- Examples: Kafka, RabbitMQ, Amazon EventBridge
Service Mesh
- Infrastructure layer for service-to-service communication
- Handles discovery, load balancing, encryption, observability
- Examples: Istio, Linkerd, Consul
Data Distribution Strategies
Sharding
Horizontally partition data across multiple databases:- Hash-Based: Use hash function to determine shard
- Range-Based: Partition by data ranges
- Geographic: Distribute by location
- Directory-Based: Lookup table maps data to shards
Replication
- Master-Slave: One write node, multiple read replicas
- Master-Master: Multiple nodes accept writes
- Peer-to-Peer: All nodes are equal
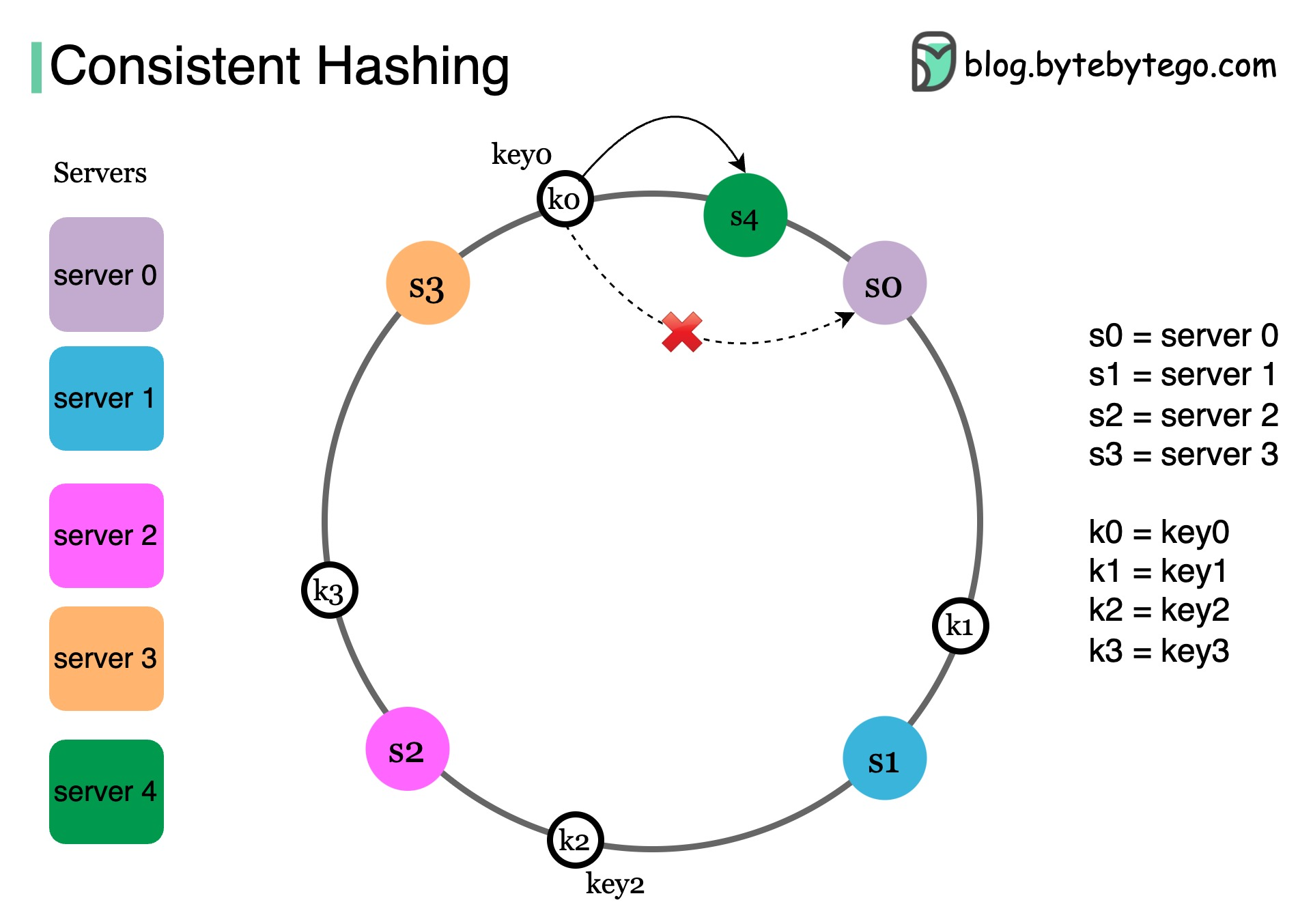
Consistent Hashing
Minimizes data movement when nodes are added/removed:- Used by DynamoDB, Cassandra, Discord
- Distributes data evenly across nodes
- Reduces rebalancing overhead
Observability and Monitoring
Three Pillars of Observability
Metrics- Numerical measurements over time
- CPU, memory, request rate, latency
- Tools: Prometheus, CloudWatch, Datadog
- Discrete events with timestamps
- Debugging and audit trails
- Tools: ELK Stack, Splunk, CloudWatch Logs
- Request flow through distributed system
- Identify bottlenecks and failures
- Tools: Jaeger, Zipkin, AWS X-Ray
Disaster Recovery
Recovery Strategies
Backup & Restore
Lowest cost, highest RTO/RPO. Regular backups to separate location.
Pilot Light
Core system running at minimum. Quick scale-up when needed.
Warm Standby
Scaled-down version always running. Faster recovery than pilot light.
Multi-Site Active/Active
Full capacity in multiple locations. Highest cost, lowest RTO/RPO.
Key Metrics
- RTO (Recovery Time Objective): Maximum acceptable downtime
- RPO (Recovery Point Objective): Maximum acceptable data loss
Failure Handling Patterns
Circuit Breaker
- Prevents cascading failures
- Stops calling failing service
- Allows time for recovery
- States: Closed → Open → Half-Open
Retry with Exponential Backoff
- Retry failed operations with increasing delays
- Prevents overwhelming recovering services
- Add jitter to prevent thundering herd
Bulkhead Pattern
- Isolate resources for different operations
- Prevent one component from consuming all resources
- Like watertight compartments in ships
Timeout
- Set time limits on operations
- Prevent indefinite waiting
- Free up resources quickly
Cloud Cost Optimization
Right-Sizing
Match instance types to actual workload requirements
Reserved Instances
Commit to long-term usage for significant discounts
Spot Instances
Use spare capacity at deep discounts for fault-tolerant workloads
Auto-Scaling
Scale down during low usage periods
Related Guides
Deepen your understanding:- CAP Theorem Explained
- 8 Must-Know Scalability Strategies
- How to Design for High Availability
- Cloud Disaster Recovery Strategies
- Cloud Cost Reduction Techniques
- Consistent Hashing
- AWS Services Cheat Sheet
- What is Cloud Native?
Building distributed systems requires careful consideration of trade-offs. There’s no silver bullet—choose patterns and technologies based on your specific requirements for consistency, availability, latency, and cost.