Documentation Index
Fetch the complete documentation index at: https://mintlify.com/ByteByteGoHq/system-design-101/llms.txt
Use this file to discover all available pages before exploring further.
Overview
A modern stock exchange must process millions of orders per second with microsecond latency. This case study explores the architectural decisions that enable such extreme performance, focusing on what must happen fast (the critical path) and what can happen later.In trading systems, every microsecond matters. High-frequency trading firms compete on nanoseconds, making architectural efficiency critical.
The Critical Path
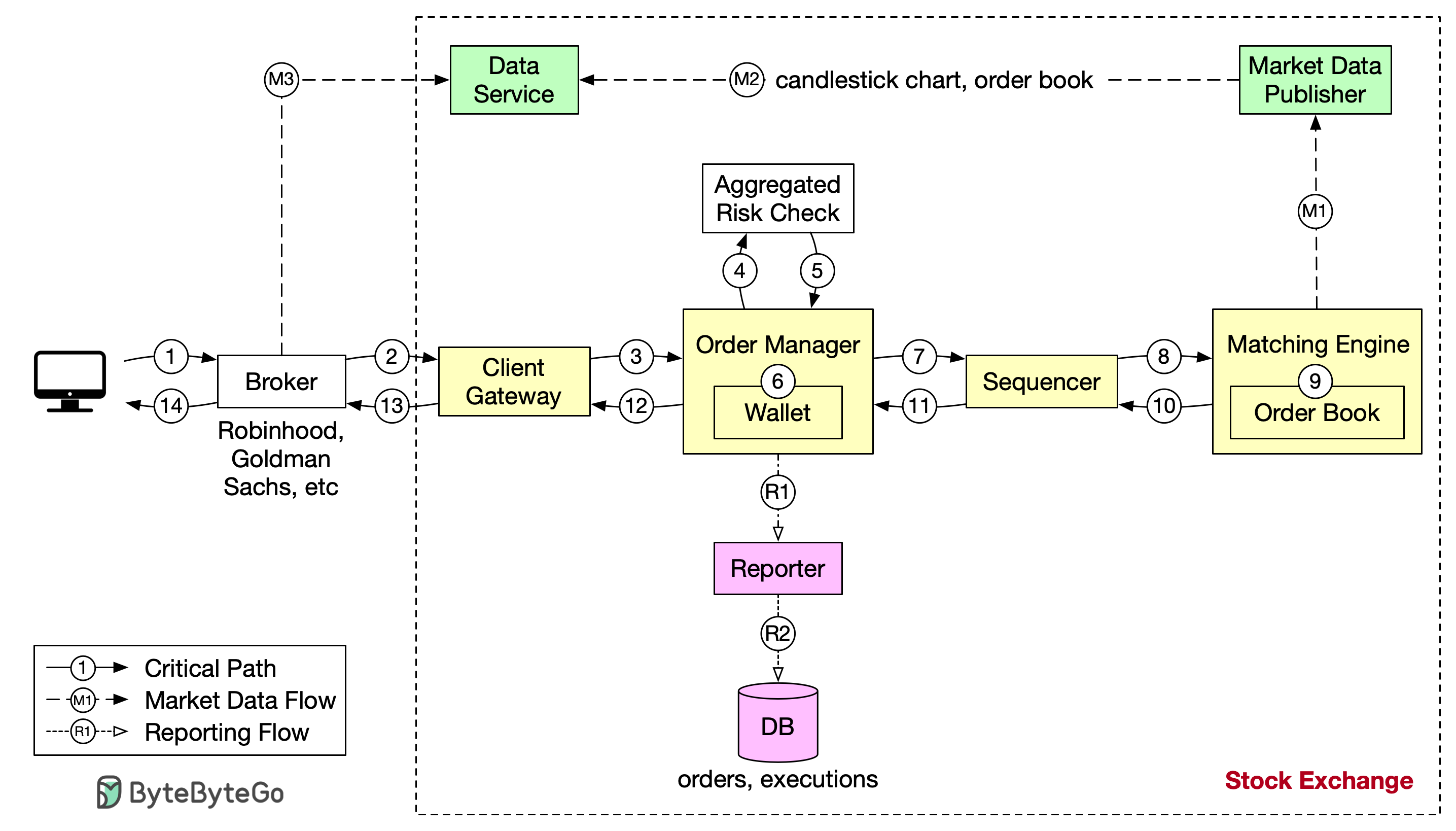
The critical path is the sequence of operations that must complete as fast as possible:Order Lifecycle: Trading Flow
Let’s trace an order through the system:Step 1: Client Places Order
A client (trader, institution, or algorithm) places an order through their broker’s web or mobile application.Order Details:
- Symbol (e.g., AAPL, TSLA)
- Side (buy or sell)
- Quantity (number of shares)
- Order type (market, limit, stop)
- Price (for limit orders)
Step 2: Broker Sends to Exchange
The broker forwards the order to the exchange through a dedicated network connection (typically using FIX protocol or proprietary binary protocols).
Step 3: Client Gateway Processing
The order enters the exchange through the client gateway.Gateway Functions:
- Input validation (correct format, required fields)
- Rate limiting (prevent order spam)
- Authentication (verify broker identity)
- Normalization (convert to internal format)
Step 4-5: Risk Checks
The order manager performs mandatory risk checks based on rules set by the risk manager.Risk Checks Include:
- Pre-trade risk limits
- Position limits (max shares held)
- Order size limits (max order size)
- Price collar checks (price within acceptable range)
- Duplicate order detection
Step 6: Wallet Verification
After passing risk checks, the order manager verifies sufficient funds in the wallet for the order.For Buy Orders:
- Check buyer has enough cash to purchase shares
- Reserve the required amount
- Check seller owns the shares
- Reserve shares for sale
Step 7-9: Order Matching
The order is sent to the matching engine, the heart of the exchange.Matching Process:
- Order enters matching engine queue
- Engine attempts to match with existing orders in the order book
- When a match is found, engine generates two executions:
- One for the buy side
- One for the sell side
Step 10-14: Return Executions
Executions are returned to the client through the same path:Return Path:
- Matching engine → Order manager
- Order manager → Client gateway
- Client gateway → Broker
- Broker → Client application
- Execution price
- Quantity filled
- Execution timestamp
- Execution ID
Non-Critical Flows
Market data flow and reporting flow are NOT on the critical path. They have different (more relaxed) latency requirements.
Market Data Flow
- Publishes order book updates to market data consumers
- Broadcasts trade executions
- Updates indices and statistics
- Latency requirement: Milliseconds (1000x slower than trading flow)
Reporting Flow
- Regulatory reporting
- Audit logging
- End-of-day settlement
- Latency requirement: Seconds to minutes
Achieving Microsecond Latency
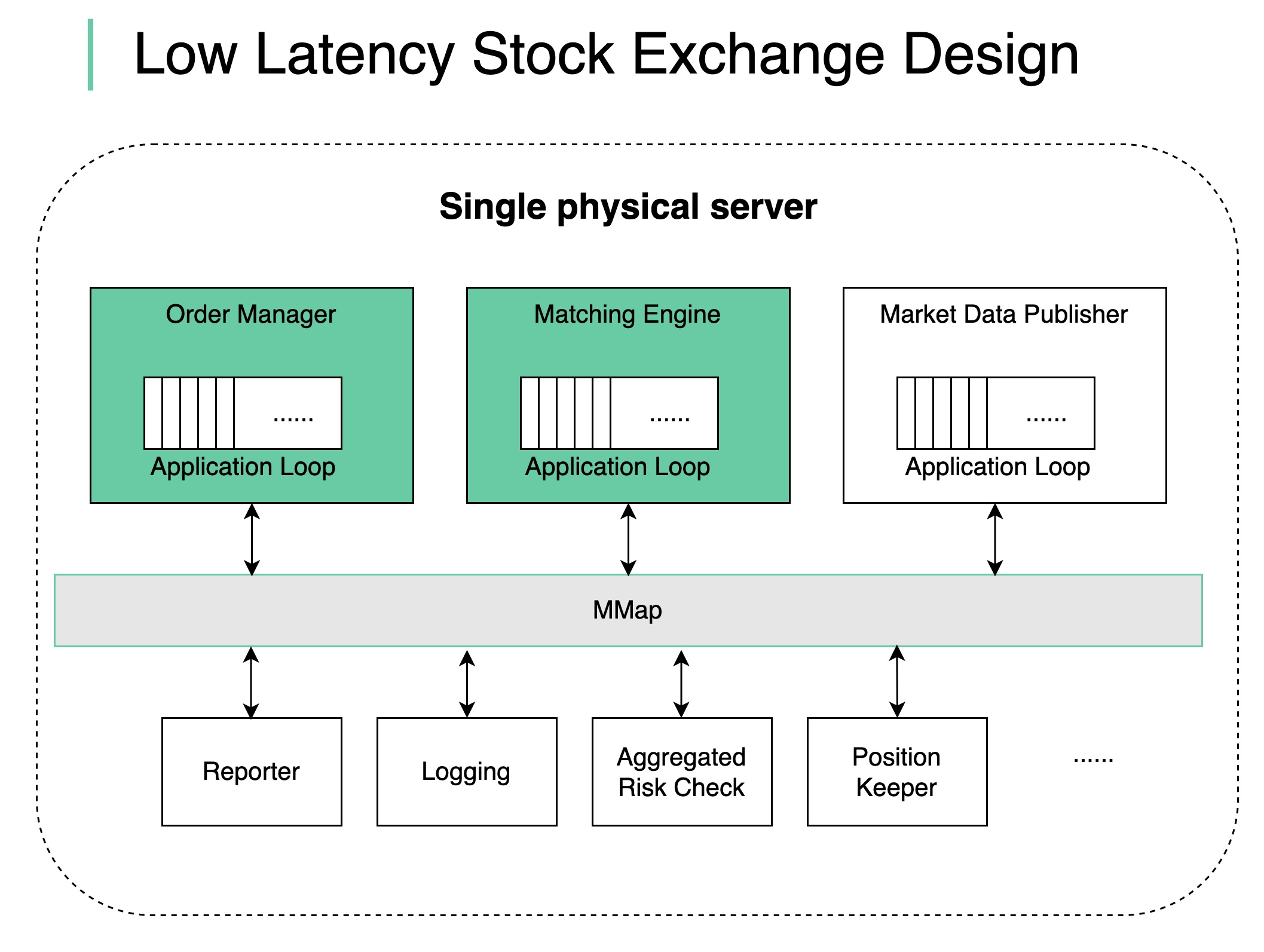 How does a modern stock exchange achieve microsecond latency?
How does a modern stock exchange achieve microsecond latency?
Core Principle: Do Less on the Critical Path
Fewer Tasks
Remove all non-essential operations from the critical path
Less Time Per Task
Optimize each operation to nanoseconds
Fewer Network Hops
Minimize inter-service communication
Less Disk Usage
Avoid disk I/O on critical path (use memory)
Low-Latency Architecture Design
1. Single Giant Server (No Containers)
Decision: Deploy all critical components on a single physical server Rationale:- No network latency between components
- No containerization overhead
- Direct memory access
- Predictable performance
- 256+ GB RAM
- Multiple CPUs (32+ cores)
- 10-25 GbE network cards
- NVMe SSDs for non-critical storage
2. Shared Memory Event Bus
Decision: Use shared memory for inter-component communication Benefits:- No network overhead
- No serialization/deserialization
- No disk I/O
- Nanosecond latency
3. Single-Threaded Components
Decision: Key components (Order Manager, Matching Engine) are single-threaded on the critical path Why Single-Threaded?No Context Switching
No Context Switching
Multi-threaded:
- OS context switches between threads
- Context switch takes ~1-10 microseconds
- Unpredictable scheduling
- Thread never context switches
- Predictable execution
- Deterministic performance
No Locks
No Locks
Multi-threaded:
- Requires mutexes/locks for shared state
- Lock contention causes delays
- Risk of deadlocks
- No shared state to protect
- No locks needed
- No contention
CPU Pinning
CPU Pinning
Each single-threaded component is pinned to a dedicated CPU core:Benefits:
- No context switches
- Better CPU cache utilization
- Predictable performance
4. Event Loop Architecture
Single-threaded application loop executes tasks sequentially:- Sequential execution (no race conditions)
- Deterministic (same inputs → same outputs)
- Can be replayed for disaster recovery
5. Other Components as Listeners
Decision: Non-critical components listen on the event bus and react accordingly Examples:- Market Data Publisher: Listens for executions, publishes to market data feed
- Risk Monitor: Listens for fills, updates position tracking
- Audit Logger: Listens for all events, writes to disk asynchronously
- Settlement: Listens for end-of-day, initiates clearing process
The Matching Engine
The matching engine is the most performance-critical component.Order Book Data Structure
Requirements:- Fast insertion: O(log n) or better
- Fast deletion: O(log n) or better
- Fast matching: O(1) to find best bid/ask
- Hash map: Price level → Order list
- Sorted list: Price levels in order
- Linked list: Orders at each price level (FIFO)
Matching Algorithm
For Market Orders (buy at any price):Matching Priorities
- Price: Better prices matched first
- Time: At same price, earlier orders matched first (FIFO)
- (Optional) Size: Some exchanges give priority to larger orders
Design Tradeoffs
Single Server vs. Distributed
Single Server vs. Distributed
Single Server (Chosen):
- ✅ Ultra-low latency (microseconds)
- ✅ No network overhead
- ✅ Simpler architecture
- ❌ Single point of failure
- ❌ Limited by single machine capacity
- ✅ Higher availability
- ✅ Better scalability
- ❌ Network latency (milliseconds)
- ❌ Coordination overhead
Single-Threaded vs. Multi-Threaded
Single-Threaded vs. Multi-Threaded
Single-Threaded (Chosen):
- ✅ No locks, no contention
- ✅ Deterministic execution
- ✅ Easier to reason about
- ❌ Can’t utilize multiple cores for same task
- ✅ Better CPU utilization
- ✅ Higher theoretical throughput
- ❌ Lock contention
- ❌ Context switching overhead
- ❌ Non-deterministic
Memory vs. Disk
Memory vs. Disk
Memory-Only (Chosen for critical path):
- ✅ Nanosecond access times
- ✅ No I/O wait
- ❌ Data loss on crash
- Use event sourcing (append-only log)
- Asynchronously replicate to disk
- Replay from log on recovery
- Maintain hot standby
Consistency vs. Speed
Consistency vs. Speed
Challenge: Ensure fairness without sacrificing speedSolution: Sequencing
- Assign sequence numbers to all orders
- Assign sequence numbers to all executions
- Process in strict sequence number order
- Enables deterministic replay
- Proves regulatory compliance
Disaster Recovery
Event Sourcing
Approach: Store every event (order, cancel, execution) in an append-only log Benefits:- Complete audit trail
- Can replay to reconstruct state
- Regulatory compliance
- Debug production issues
Hot Standby
Architecture:- All events written to event log
- Events replicated to standby server
- Standby replays events in real-time
- On primary failure, standby takes over
Performance Metrics
Latency Targets
- Order validation: < 10 microseconds
- Risk checks: < 20 microseconds
- Order matching: < 50 microseconds
- End-to-end: < 100 microseconds (order in → execution out)
Throughput
- Orders per second: 1-10 million
- Messages per second: 10-100 million (including market data)
- Peak burst: 100+ million messages/second
Availability
- Uptime: 99.99% during trading hours
- Planned downtime: Outside trading hours only
- Failover: < 10 seconds
Key Technologies
Shared Memory
Lock-free ring buffers (LMAX Disruptor pattern)
Event Sourcing
Append-only event log for recovery and audit
CPU Pinning
Dedicate CPU cores to critical components
FIX Protocol
Financial Information eXchange protocol for order communication
Summary
Designing a stock exchange for microsecond latency requires:Identify Critical Path
Clearly separate what must be fast (trading) from what can be slower (reporting)
Minimize Overhead
- Single server (no network)
- Shared memory (no serialization)
- Single-threaded (no locks)
- CPU pinning (no context switches)
Stock exchanges sacrifice some traditional distributed systems benefits (high availability, horizontal scalability) to achieve extreme low latency. The tradeoff is acceptable because trading only happens during market hours, and hot standby provides sufficient redundancy.